NLP Evaluation
BLEU
2001年提出,当时的应用场景是解决机器翻译。
基础 $BLEU_n$ 模型
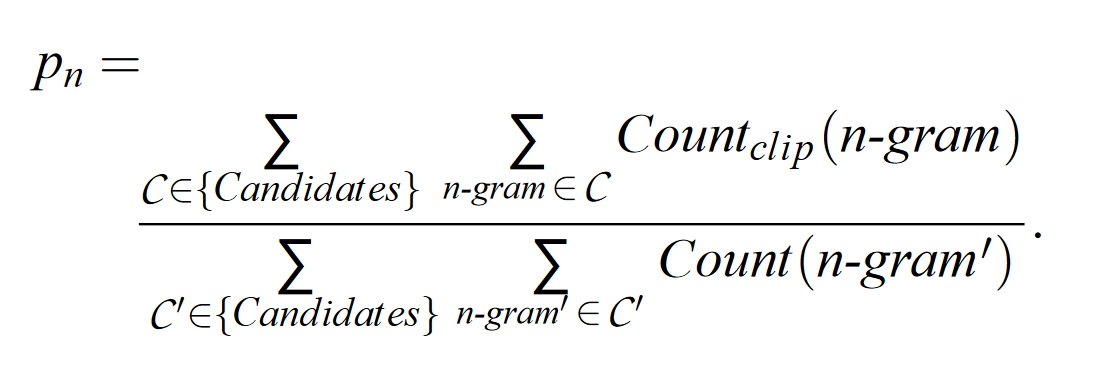
分母的含义是 n-gram 词在 candidate 中有多少个,分子的含义是这些词有多少出现在了 reference 中
问题与改进
统计次数时要求 Candidates 中一个词的最大次数不能超过 Reference 中所有该词的次数和,如下面这个例子

对前 n-gram 个评价方法先取对数再线性平均得到综合后的 n-gram 评分,取对数的原因是因为单个 n-gram precision 呈指数下降,先对数再平均相当于求几何均值
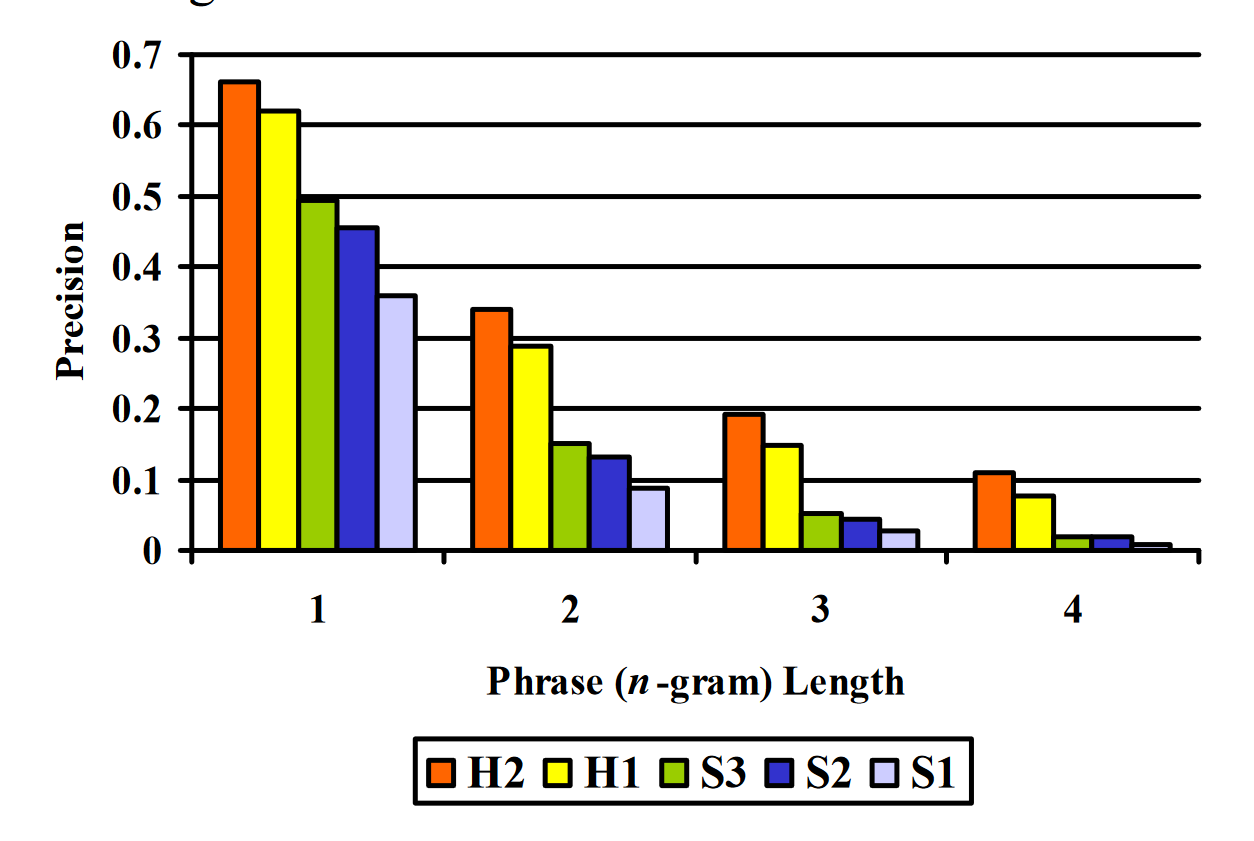
BLEU模型还不能解决句子长度过小的问题,如下面这个例子

将概念而非词作为一个最小单元来计算,可以更好的表示 candidate 语义的 precision,这样可以解决一个句子中多义词重复出现的问题,但这种方法受制于句子长短、语序语法等问题。

- 针对句子长度过短的惩罚问题,要在得分前面乘以一个不大于1的系数BP,其中 $r$ 为所有候选句子”最佳匹配长度“(best match lengths,定义为 reference 中和候选句子长度最接近的句子长度),$c$ 为 candidates 的总长度
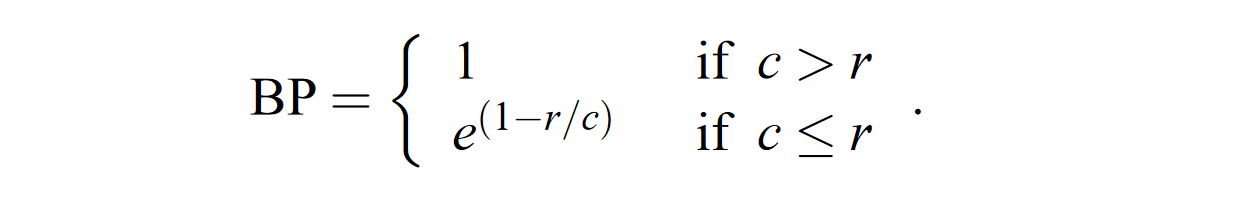
最终计算式
$N$ 为选择的最高语言模型元数,$w_n$ 为归一化系数,原论文 baseline 给出的是 $N=4,W_n = 1/N$
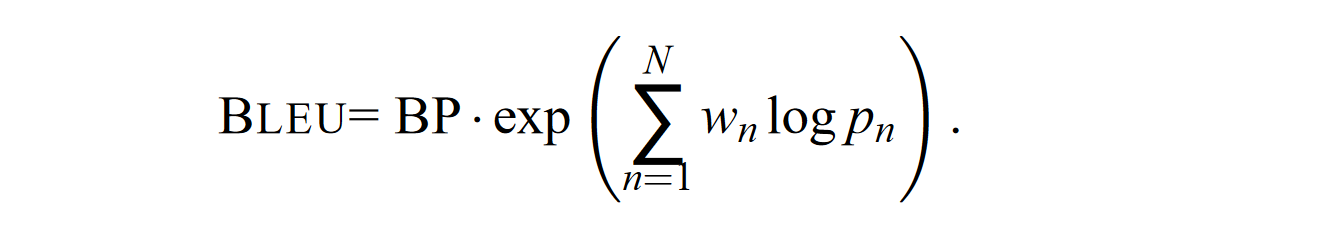
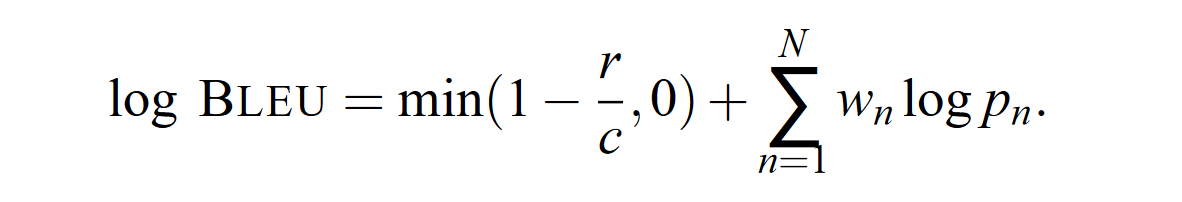
模型评价
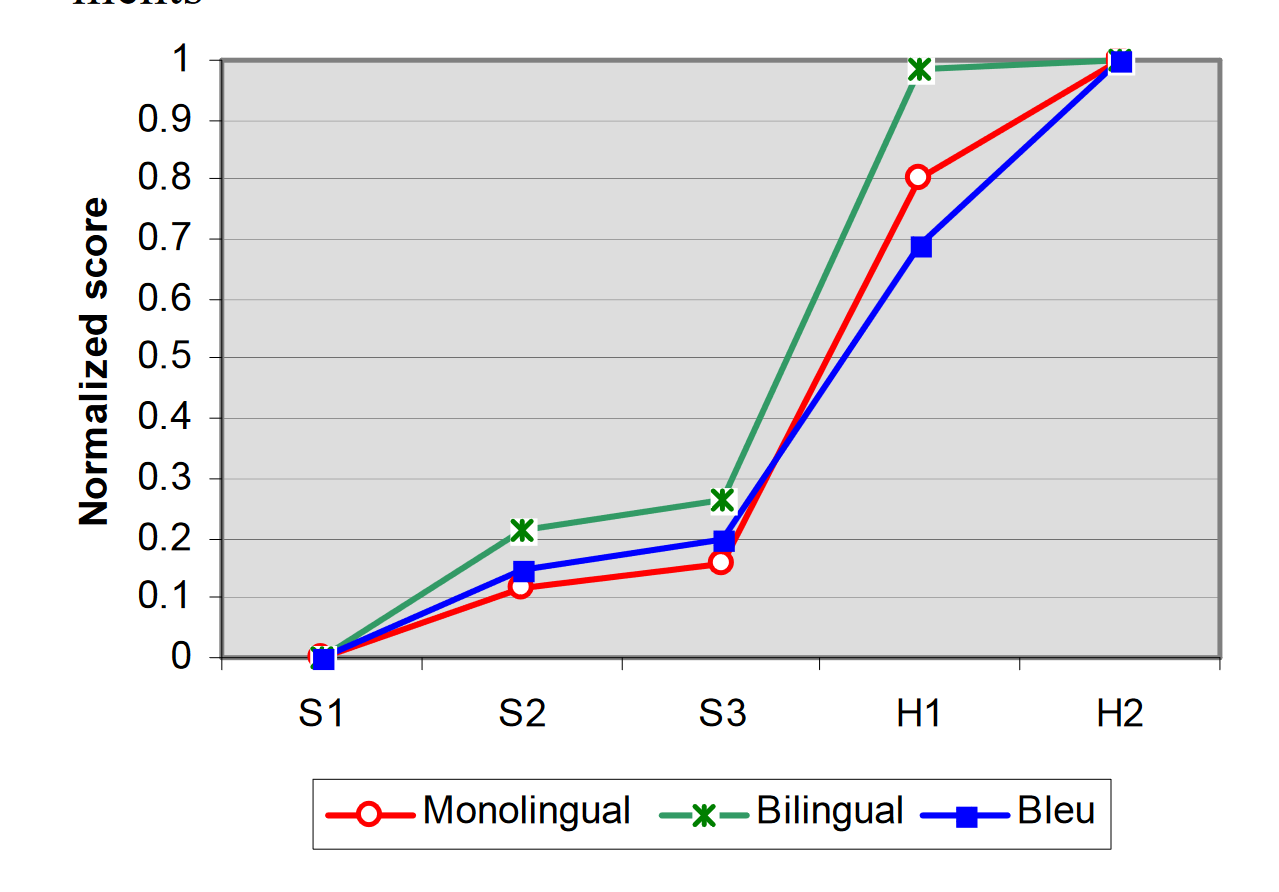
双语玩家、母语玩家和 BLUE 的 PK 结果
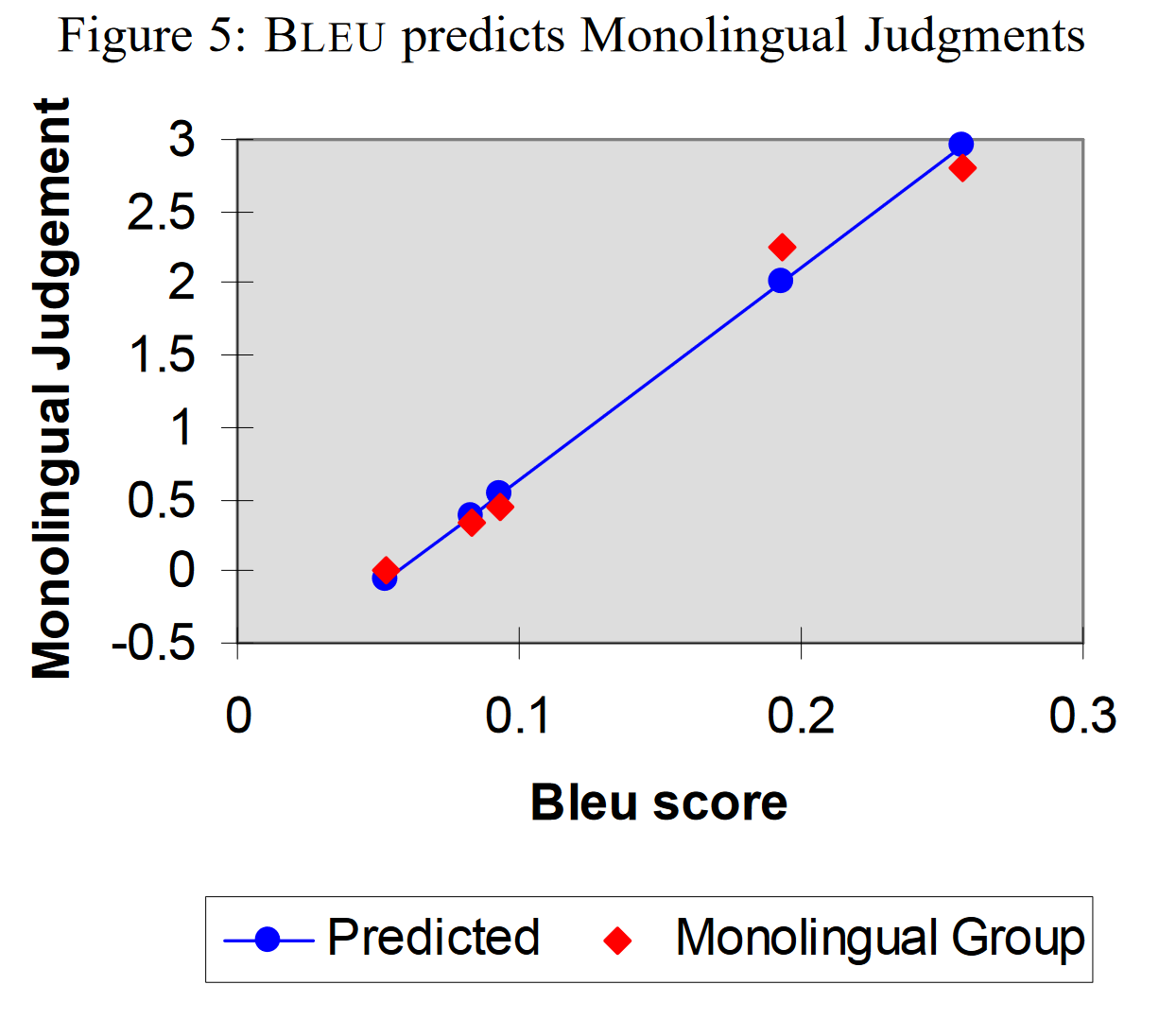
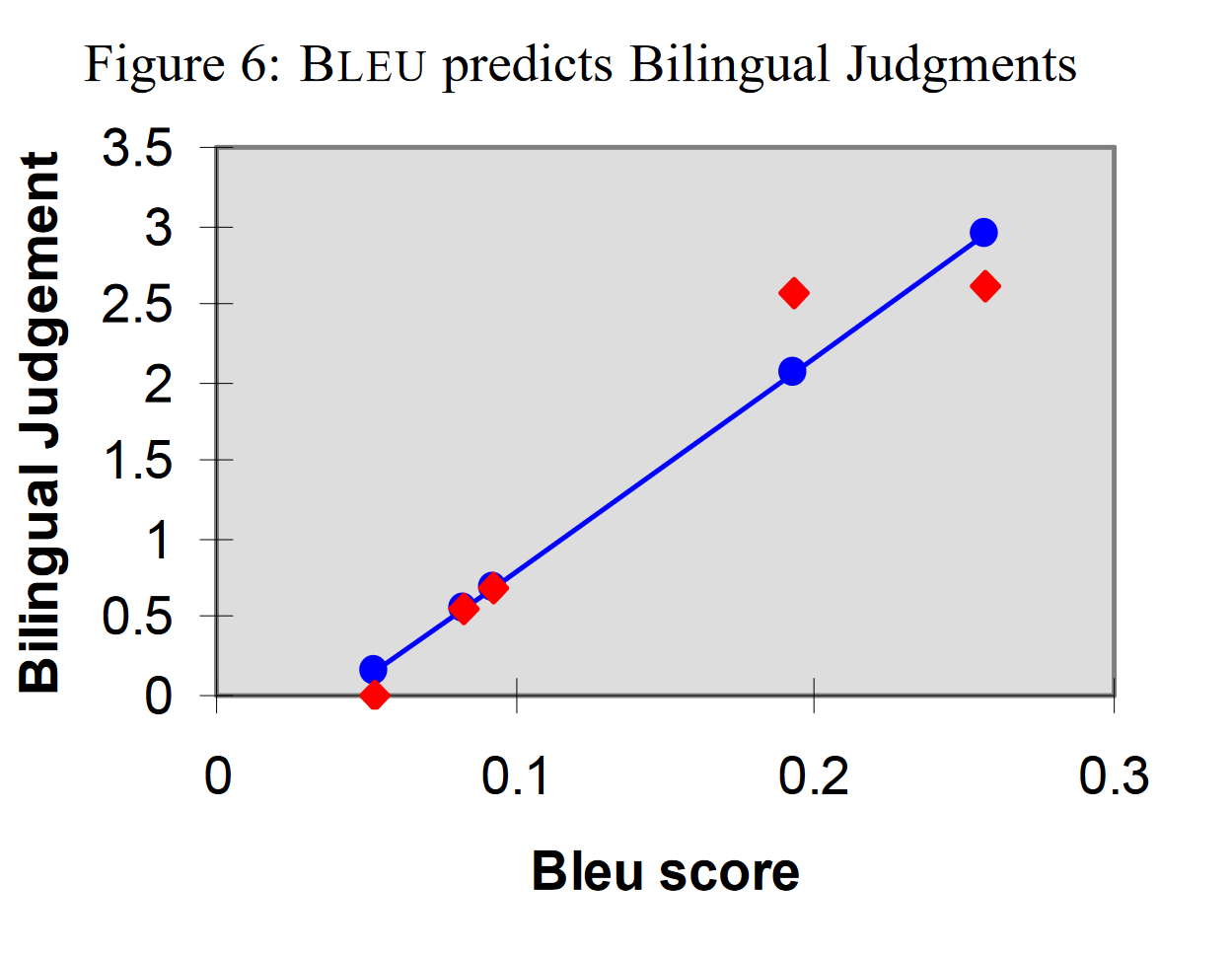
BLEE预测稳定性以及可靠性的问题:Table 1展示的是每一组 candidates 结果的 BLEU 分数,Table 2 展示的是每一组 candidates (容量为500)拆成二十个小的样本以后,得分的均值方差,以及和前一次测试的 t-paired test 结果(比如 S2 就是和 S1 做 t-paired test),考虑到 t-paired test 的 95% 拒绝域为 1.7,因此可以说明每一组评分都具有显著性差异
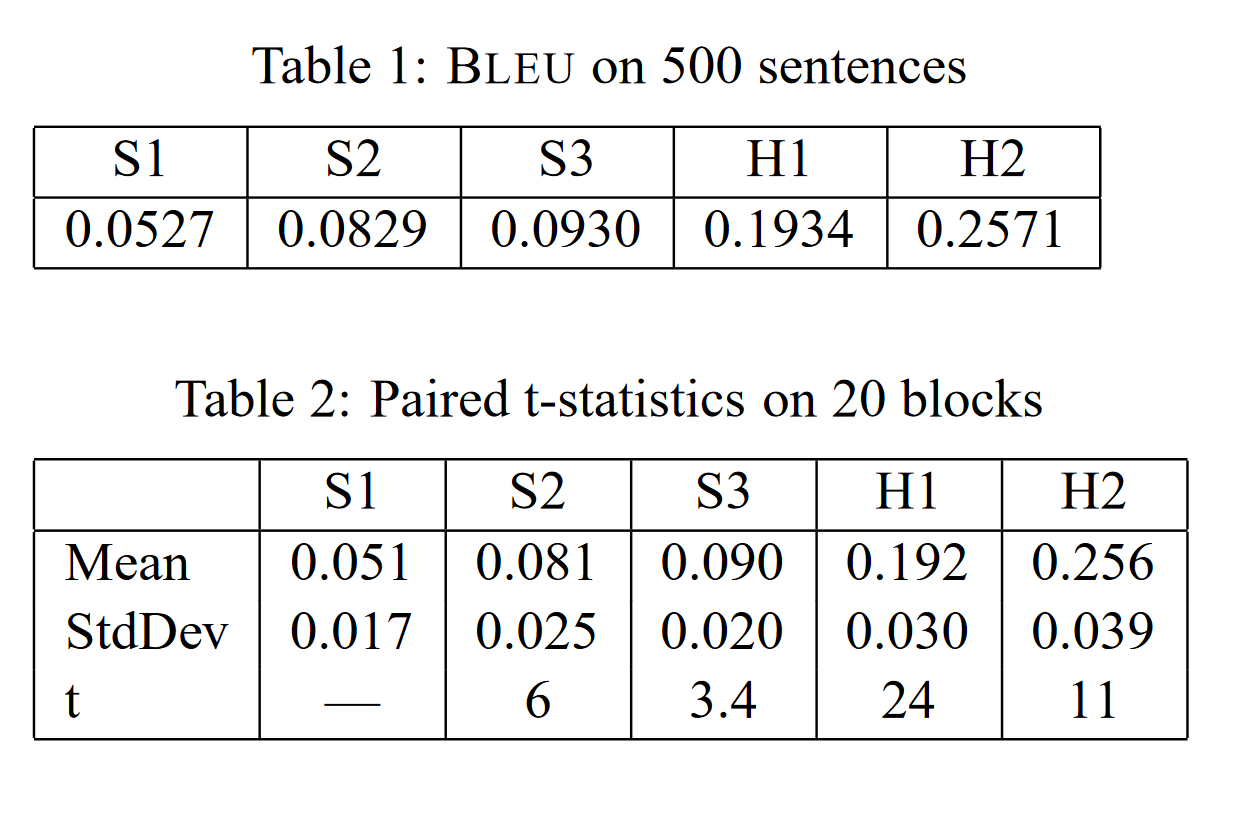
BLEU的一些特点:只关心准确率,不关注召回率(因此 BLEU 论文作者建议给 4 条reference,同时 brevity penalty 也在一定程度上起到了惩罚召回率的作用),偏向翻译相对较短的结果(brevity penalty 没有想象中那么强)
ROUGE
2003年提出,关于它的意义,一种理解是在 SMT(统计机器翻译)时代,机器翻译效果稀烂,需要同时评价翻译的准确度和流畅度;等到 NMT (神经网络机器翻译)出来以后,神经网络脑补能力极强,翻译出的结果都是通顺的,但是有时候容易瞎翻译。
ROUGE-N
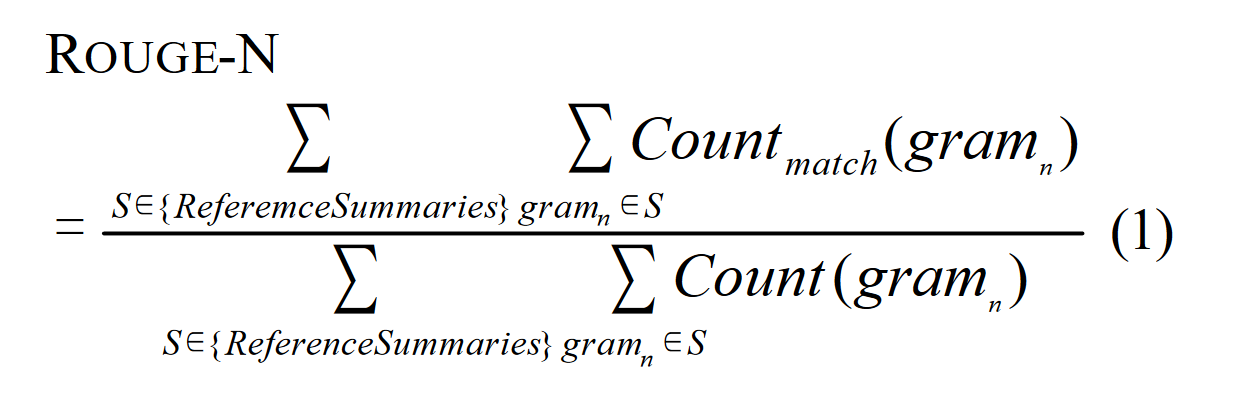
分子表示 n-gram 下,reference 中和 candidate summary (候选摘要,就是从 candidates 中抽取出一些)的重合个数,分母表示 reference 中总的词个数。
对于多个 reference 的情况,将得分设置为对每个 reference 单独应用 ROUGE-N 算法后再取最大值。
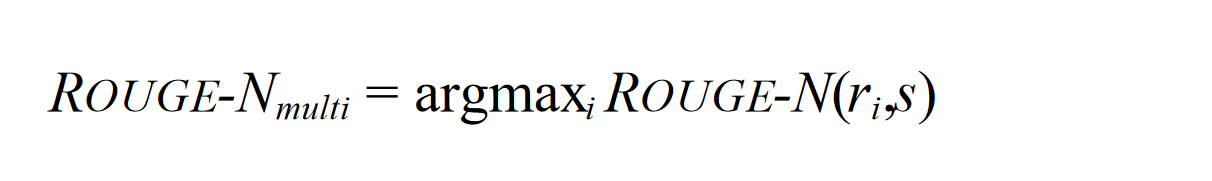
计算得分还可以通过 Jackknife (一种再抽样方法,可以降低误差)方法得到更接近人类评判的结果,但对于一般计算来说取最大值就可以了。
ROUGE-L
Rouge-L 的 L 表示: Longest Common Subsequence,Rouge-L 的计算利用了最长公共子序列(区别一下最长公共子串,这个是连续的,子序列不一定连续,但是二者都是有词的顺序的)。
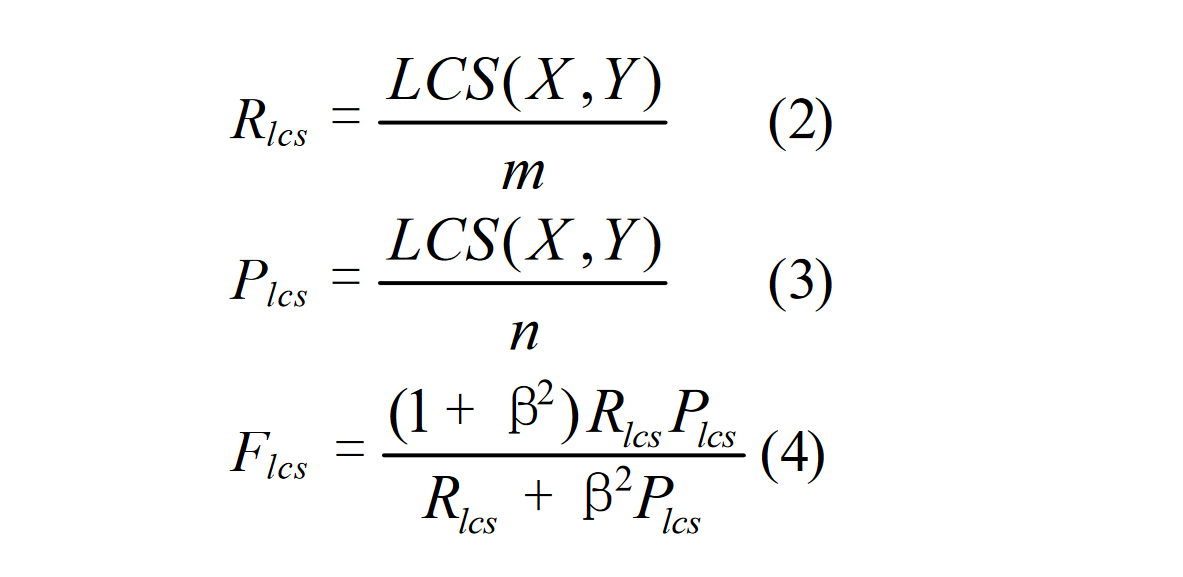
上面的式子中,$X$,$Y$ 分别表示标准答案 reference 和生产答案 candidate 。$m$,$n$ 表示 $X$ 和 $Y$ 的长度,$\beta$ 为一个超参数,LCS 表示二者的最大公共子序列,$R_{lcs}$ 实际上就是改进后的召回率一般超参数 $\beta$ 都会设置的比较大,召回率对评分的影响较大,也符合 ROUGE 的初衷。
对于 summary 层面,将 summary 求并后再求 CLS 应用上式
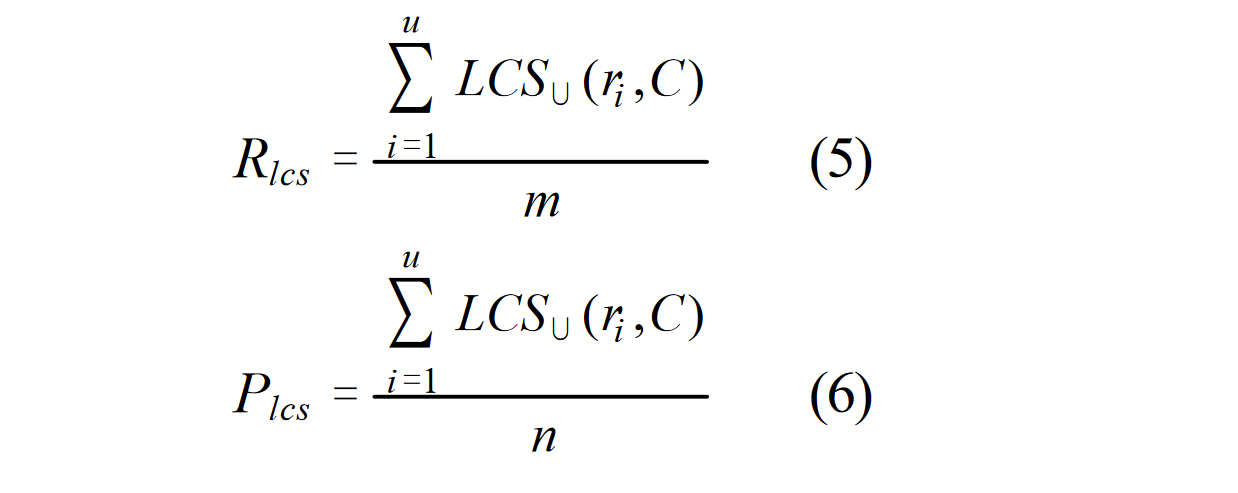
ROUGE-W
增加了对正确结果连续性的奖励,比如下面这个例子中,$Y_1$ 和 $Y_2$ ROUGE-L 得分一致,但显然 $Y_1$ 翻译结果更好
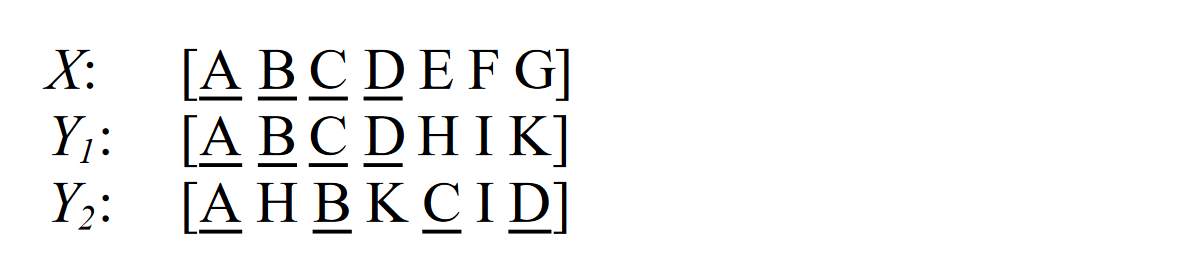
计算式:
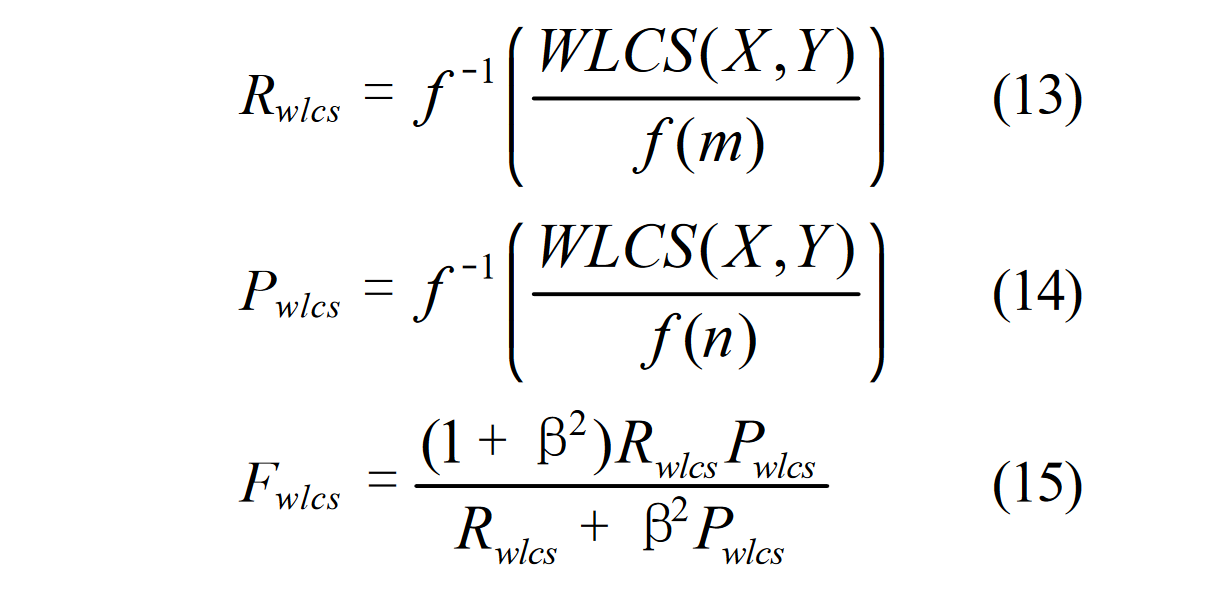
ROUGE-S
Rouge-S的S表示:Skip-Bigram Co-Occurrence Statistics,这其实是Rouge-N的一种扩展,N-gram是连续的,Skip-bigram是允许跳过中间的某些词,同时结合了 Rouge-L 的计算方式。下面是以二元模型为例
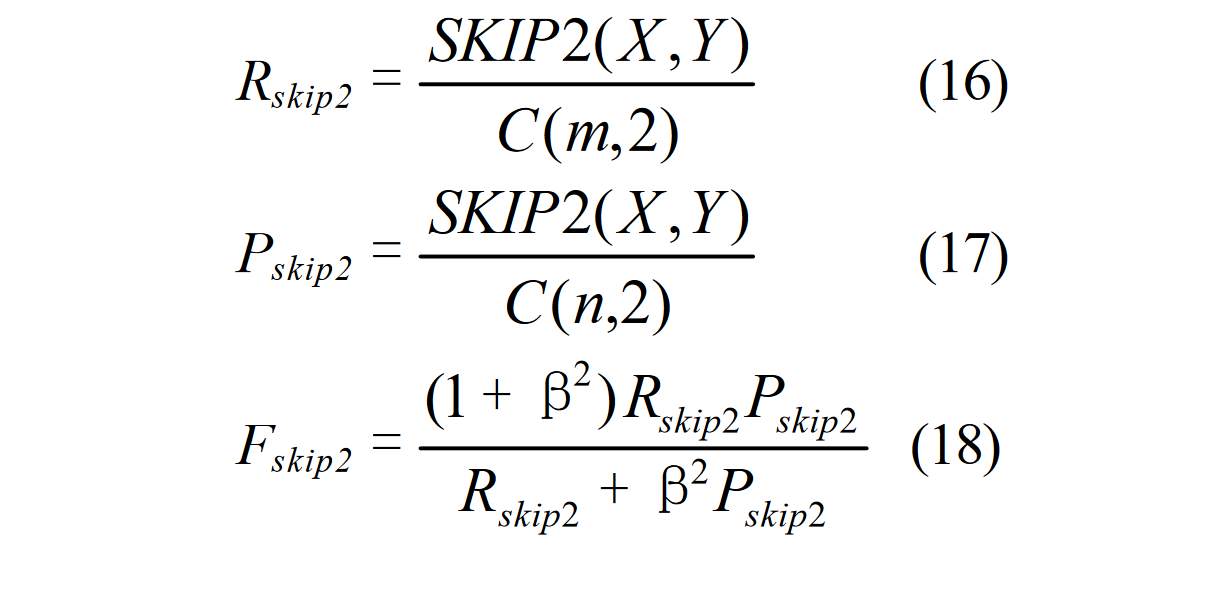
$C(m,2),C(n,2)$ 就是 $X,Y$ 中二元跳词可能出现的种类个数,$SKIP2(X,Y)$ 就是统计二者在跳词层面相同的个数。
问题和评价
这种方法只能在单词、短语的角度去衡量两个句子的形似度。并不能支持同义词、近义词等语意级别去衡量。比如:

hyp1和hyp2的rouge得分是一样的。但显然hyp1才是与ref更相近的。好处是这种方式计算高效,在忽略近义词等情况下,做到比较合理的判断。
NLP评估指标之ROUGE - 知乎 (zhihu.com)
METEOR
2004年提出,考虑准确率和召回率的基础上,对词序要求更严格
METEOR 的提出主要是为了解决 BLEU 的这些问题:
- 召回率
- 句子流畅性
- 同义词对语义的影响
一些问题:
- BLEU 和 METEOR 对长度都比较敏感
计算式
三种匹配规则
- 词映射(exact):统计待测译文与参考译文中绝对一致单词的共现次数
- 词干映射(porter stem):基于波特词干算法计算待测译文与参考译文中词干相同的词语“变体”的共现次数
- 同义词映射(WN synonymy) :基于WordNet词典匹配待测译文与参考译文中的同义词,计入共现次数
第一个阶段,通过额外的 module 列出所有可能的 unigram 映射,比如,对于词 ’computer’ ,在 candidate 中出现了一次,而在 reference 中出现了两次,则列出两个可能的 unigram 映射,一个是 candidate 中的 ’computer’ 映射到 reference 中的第一个 computer ,另一个则是映射到第二个 computer 。
第二阶段中,选择这些 unigram mapping 的最大的子集使得满足之前的条件(即每个unigram有1个或0的对应),如果多于一个子集满足了这个条件,METEOR选择有最少 unigram mapping crosse 的那个,mapping crosses 定义为,将两句话写成两行,然后将 mapping 连起来,每个交叉的位置就是一个 mapping cross
每个阶段仅仅 map 那些在前一阶段没有匹配的 unigram,第一阶段先进行 exact mapping,第二阶段进行 porter stem mapping,最后进行 WN synonymy mapping
得到最后的映射后,就可以计算METEOR得分了,首先计算unigram precision,它是匹配的unigrams对数占candidate中unigram的比例,再计算unigram recall,它是匹配的unigrams对数占 reference 中的unigram的比例,然后用调和均值的方式计算Fmean。
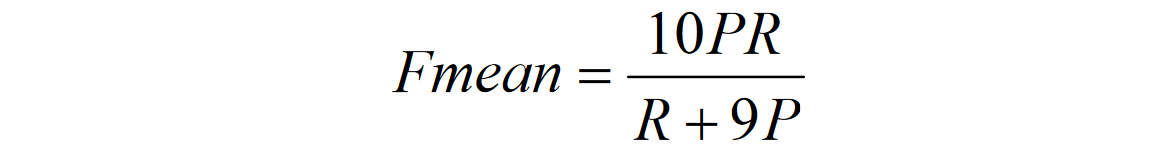
为了考虑 n-grim 匹配,METEOR设计了一种惩罚策略,首先,所有candidate中映射到reference中的unigram被分组为尽可能少的chunks中,使得在candidate中的每个毗邻的chunk在reference中也毗邻,这样,n-gram越长,则chunk就越少,极端情况下就是只有1个chunk,另一个极端就是没有bigram匹配,则就会有很多chunk
例如:
candidate:the president spoke to the audience
reference:the president then spoke to the audience
这就有两个chunk,”the president“和”spoke to the audience“
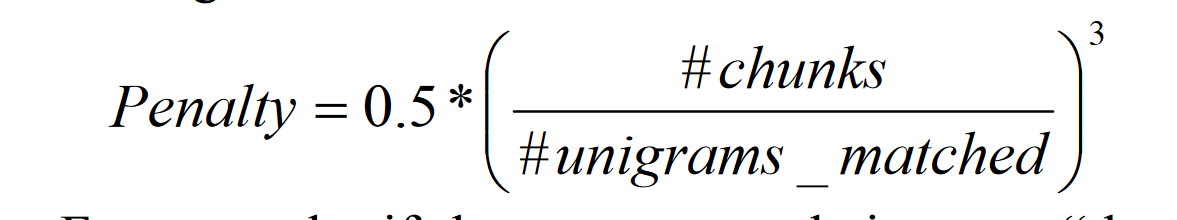
最后的计算公式为
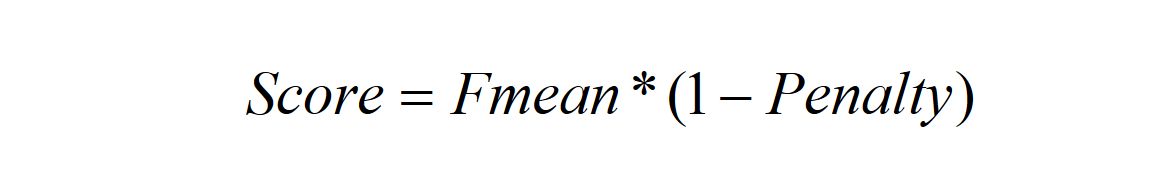
如果没有bigram或者更长的匹配,Fmean会被削减最多50%,METEOR对于一组reference,计算candidate和其中每个的得分,最后选择其中最大的那个,对于整个系统的评估,METEOR计算累积 precision,recall和penalty,然后再将他们结合为最终评分。
CIDEr
2015年提出,当时是为了给图像-字幕生成过程中对字幕质量打分,具体的问题就是一个图片会生成很多的字幕,然后需要一种算法来判断哪种字幕和 reference 的最像。
CIDEr的一个重要思想就是基于TF-IDF去给不同的n-gram赋予不同的权重,降低频繁词的权重并升高关键词的权重
计算式
TF-IDF 模型
假设对于一组图片集$I$,每个图片生成一句话 $c_i$ 作为字幕,同时对于每一个图片又有 m 个参考字幕 $S_i = {s_{i1},s_{i2}\cdots s_{im}}$,对于 $s_{ij}$ 中的每一个 n 元词组 $w_k$,其 TF-IDF 权重 $g_k(s_{ij})$ 计算方式如下
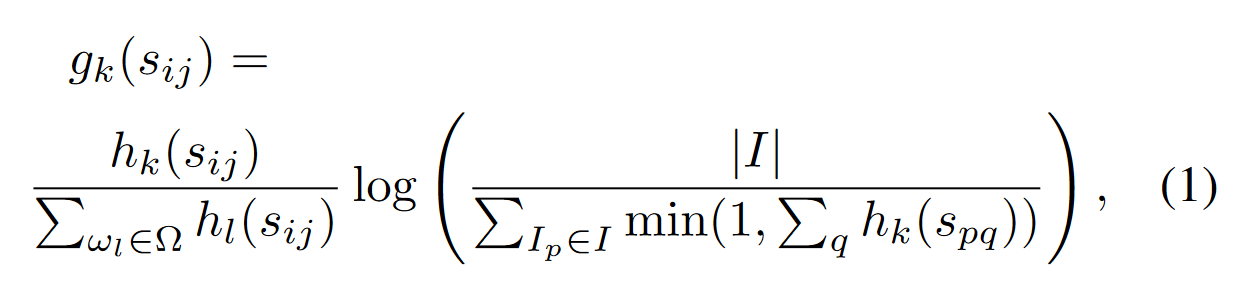
$\Omega$ 表示这一句话中所有 n-gram 的全部词汇,$|I|$ 表示图像个数,$k$ 第 k 个图像。
前半部分称为TF (term frequence),一般来说一个词在文档中出现的越多,TF值就越高。这部分是为了筛选出关键字。
后半部分称为IDF (inverse document frequency),如果一个n-gram在所有文档中出现的次数越多,则IDF值越低。这部分是为了去掉那些频繁出现的无意字(比如的地得这种语气助词)
当有TF(词频)和IDF(逆文档频率)后,将这两个词相乘,就能得到一个词的TF-IDF的值。某个词在文章中的TF-IDF越大,那么一般而言这个词在这篇文章的重要性会越高,将一句话中每一个 n-grim 词的的 TF-IDF 都算出来,可以组成一个长度为句子长度的向量,为了保证向量长度一致,真正计算过程中,会通过对长度较小的句子进行补零操作以对齐向量维度
- 举例:
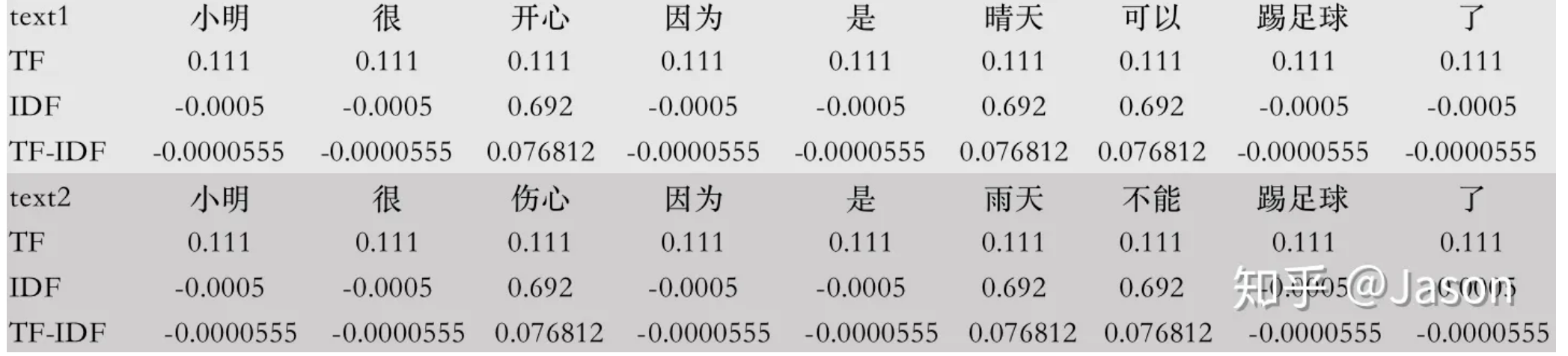
句子1:小明很开心,因为是晴天,可以踢足球了
句子2:小明很伤心,因为是雨天,不能踢足球了。
所有词的 TF-IDF 如下
最后能够得到的向量表示如下

CIDEr
CIDER就是对每个参考或者候选句子都计算TF-IDF 向量(只不过 term 是 n-gram 而不是单词),然后对于每一张图片的一个 candidate, 计算其和剩下 m 个 reference 的余弦夹角,并据此得到候选句子和参考句子的相似度。
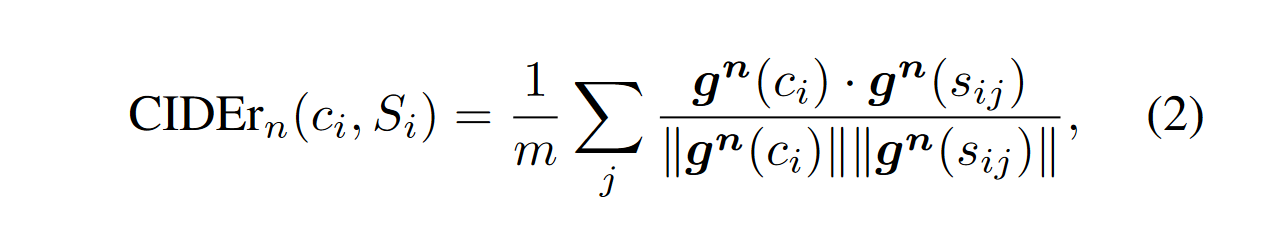
和BLEU、ROUGE一样,CIDEr也可以计算不同n-gram的聚合:
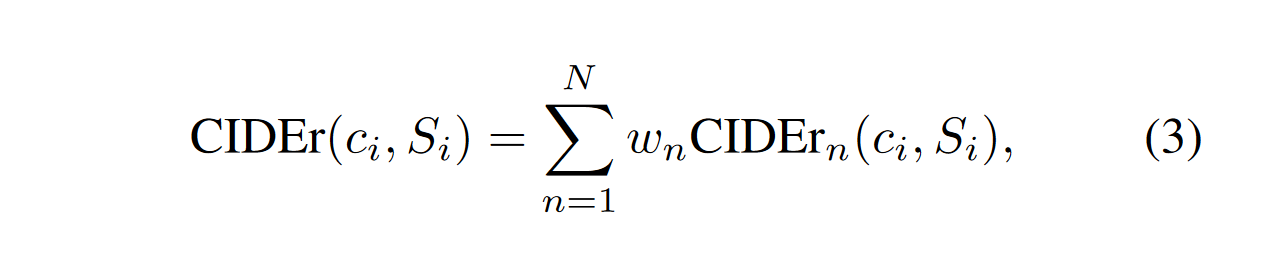
经验性的,baseline 参数设为 $w_n = 1/N, N=4$,这一点和 BLEU 一致。
一些实验结果
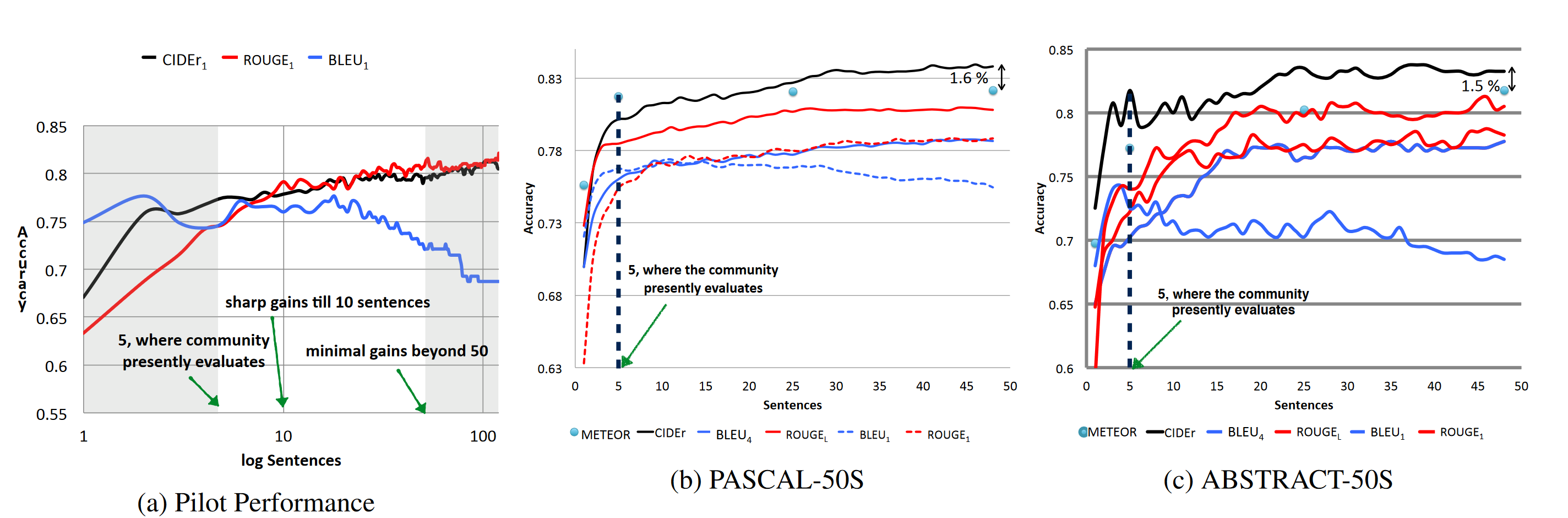
左图表示的是对比人类判断和 CIDEr、ROUGE、BLEU 算法判断准确率与 reference 句子长度的关系,可以看到,参考句子数量较少时 BLEU 表现很好,但随着句子数量增加(注意横坐标是取了对数的,实际句子数量很大), CIDEr 和 ROUGE 的准确性稳步提升,这是因为二者相比BLEU对reference都有更深刻的理解,此外,收益在50左右饱和。
修改优化
为了解决 gaming 的问题(针对某一种评价指标来优化算法使得当人类给出的分很低,但是评价指标给出的分很高)
- 去除句子中的单词转换为原始形式这一步,保证时态正确
- 加入了高斯因子,用于惩罚candidate和reference sentence长度相差较大的情况。
- 重复高置信度(即信息含量较多的句子,比如图片有一条鱼,那句子重复说fish的情况)的单词的句子加惩罚。例如对于某个指定的n元组来说,取该n元组在candidate和reference sentence出现次数最小的数。(类似于Bleu的操作)
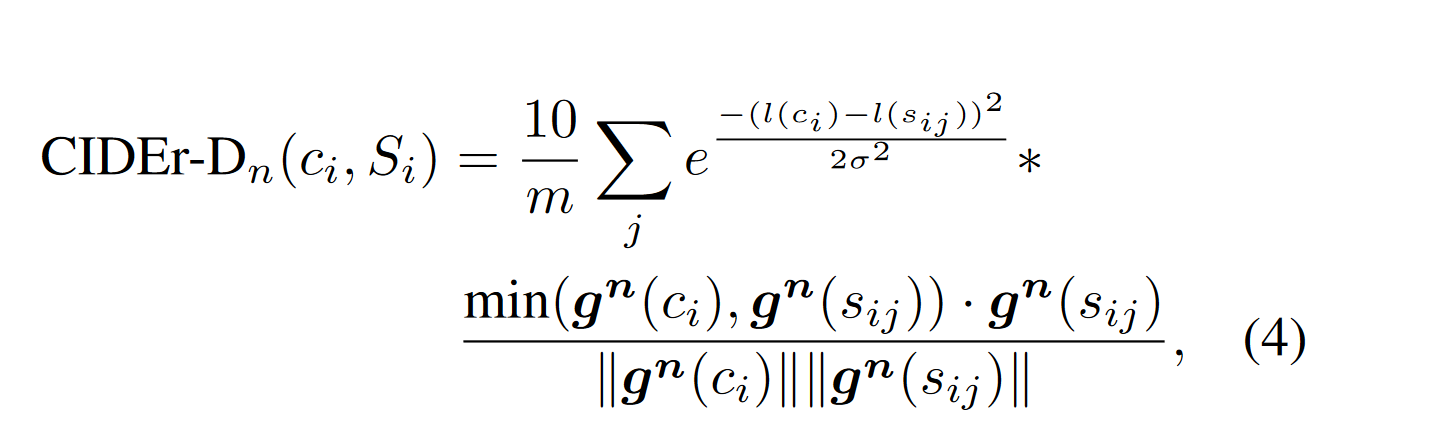
$l(c_i)$ 和 $l(s_{ij})$ 表示句子长度,$\sigma$ 一般取 6,式子前面乘10是为了让 CIDEr-D 得分和其它方法差不多。
机器学习:生动理解TF-IDF算法 - 知乎 (zhihu.com)